CQRS and Event Sourcing: A Practical Introduction
CQRS separates read and write models for independent optimization. Event Sourcing stores every state change as an immutable event. Learn when each pattern solves real problems, with TypeScript implementations, projection examples, and event store comparisons.
Infrastructure engineer with 10+ years building production systems on AWS, GCP,…
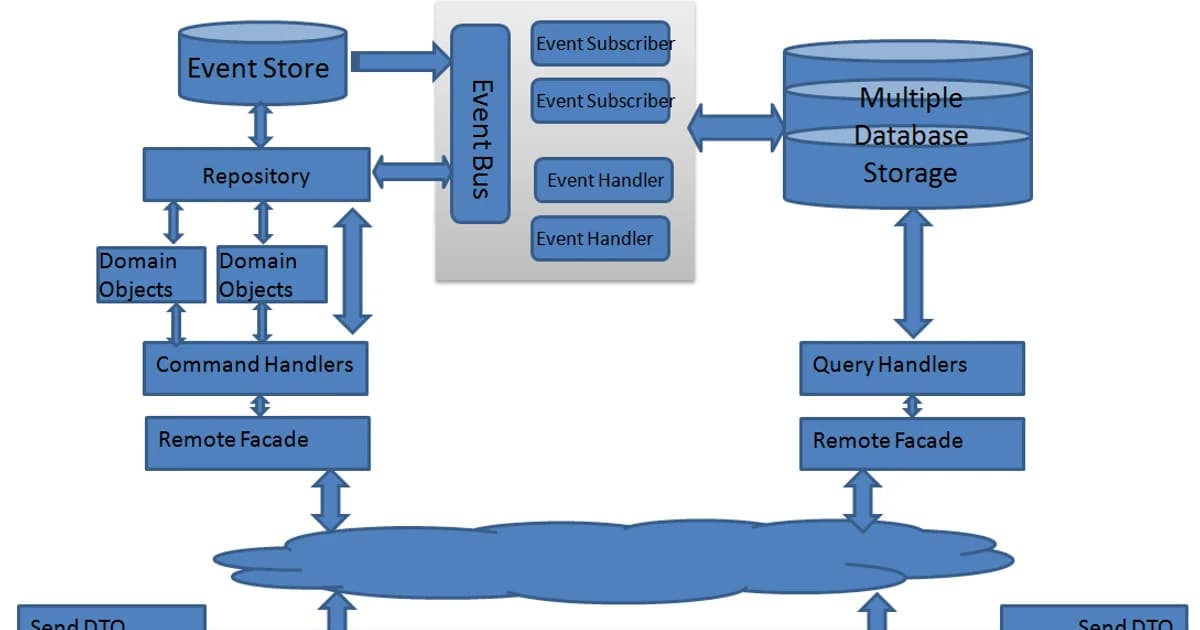
Before You Read Any Further -- The Three-Question Filter
Most articles about CQRS and Event Sourcing bury the lead. This one will not. Answer these three questions first, because they determine whether the rest of this guide is worth your time or a trap.
- Does a regulator, lawyer, or auditor require you to prove the exact sequence of state changes? Think SEC Rule 17a-4, HIPAA 164.312(b), PCI DSS 10, EU DORA. If yes, Event Sourcing is pulling its weight. If no, keep reading -- but be honest.
- Do your reads and writes have fundamentally different shapes? Write side validates "can this customer place this order" (one aggregate, strict invariants). Read side serves "show the last 20 orders with product thumbnails and tracking status" (denormalized, joined, sorted). If the shapes are the same, you do not need CQRS. A read replica will fix whatever you thought CQRS was going to fix.
- Can your users tolerate reads that are 50-500ms stale? If the answer is "no, everything must be read-your-writes consistent everywhere," you will fight the pattern every day. Do not adopt CQRS.
Three yes answers and you have a genuine case. Two yes answers and you want CQRS without Event Sourcing. One or zero and this whole family of patterns will cost you more than it returns. I have watched four teams adopt full event-sourced CQRS on what was ultimately a CRUD app. All four ended up with a 9-month rewrite back to boring Postgres. This guide is written to keep you out of that category.
The Vocabulary, In Plain English
Both patterns suffer from vocabulary bloat. Stripping the jargon: CQRS means one model for writing, a different model for reading, with some mechanism to keep them in sync. That is it. Your write model can be a regular Postgres table. Your read model can be a materialized view, a read replica, an Elasticsearch index, or a Redis cache. There is no requirement for event logs, CQRS buses, or a message broker. The simplest CQRS in production is CREATE MATERIALIZED VIEW order_summaries AS ... plus a refresh trigger.
Event Sourcing means your source of truth is an append-only log of things that happened, not a table of current state. Instead of UPDATE orders SET status='shipped' WHERE id=123, you write OrderShipped { orderId: 123, carrier: 'FedEx', trackingNumber: 'ABC123', ts: '2026-04-07T10:30:00Z' } and never mutate it. Current state is derived by replaying events. This gives you an audit trail, temporal queries ("what was the balance on March 15?"), and the ability to rebuild any view of the data from scratch. It also gives you schema-evolution pain for the lifetime of the system.
CQRS and Event Sourcing compose -- an event-sourced system is almost always CQRS because the read models are projections over the event log. But CQRS does not imply Event Sourcing. Start by noticing which problem you actually have.
CQRS Without Event Sourcing
These two patterns are often mentioned together, but they're independent. You can -- and often should -- use CQRS without Event Sourcing.
The Simplest CQRS Implementation
- Command side: your existing write database (PostgreSQL, MySQL) handles inserts and updates with full business logic validation.
- Query side: a read-optimized view, materialized view, or separate database (Elasticsearch, Redis, a denormalized read replica) serves queries.
- Synchronization: change data capture (CDC), database triggers, or application-level events keep the read model updated.
// Command: write side with business logic
class OrderCommandHandler {
async createOrder(cmd: CreateOrderCommand): Promise {
// Validate business rules
const customer = await this.customerRepo.findById(cmd.customerId);
if (!customer.isActive) {
throw new BusinessRuleError('Inactive customers cannot place orders');
}
const order = Order.create({
customerId: cmd.customerId,
items: cmd.items,
status: 'pending',
});
await this.orderRepo.save(order);
// Publish event to update read model
await this.eventBus.publish(new OrderCreated({
orderId: order.id,
customerId: order.customerId,
items: order.items,
total: order.total,
createdAt: order.createdAt,
}));
}
}
// Query: read side optimized for display
class OrderQueryHandler {
async getOrderSummary(orderId: string): Promise {
// Read from denormalized, query-optimized store
return this.readDb.query(`
SELECT o.id, o.status, o.total, o.created_at,
c.name as customer_name, c.email as customer_email,
COUNT(i.id) as item_count
FROM order_summaries o
JOIN customer_cache c ON o.customer_id = c.id
JOIN order_item_cache i ON o.id = i.order_id
WHERE o.id = $1
GROUP BY o.id, c.name, c.email
`, [orderId]);
}
} This is CQRS in its most practical form. The command side validates and writes. The query side reads from an optimized model. No event store, no event replay, no complex infrastructure. Many teams that "need CQRS" actually need this -- separate read and write models -- and nothing more.
Pro tip: Start with CQRS without Event Sourcing. Use PostgreSQL for writes and materialized views or a read replica for reads. This gives you 80% of the benefit with 20% of the complexity. Only add Event Sourcing when you have a concrete need for audit trails, temporal queries, or event replay.
Event Sourcing: The Full Pattern
When your domain genuinely needs a complete history of state changes, Event Sourcing is the right tool. Here's how it works in an order processing system:
Event Store Structure
// Events are immutable facts
interface OrderEvent {
eventId: string;
aggregateId: string; // The order ID
eventType: string;
version: number; // Sequence number for this aggregate
timestamp: Date;
data: Record;
}
// Example event stream for a single order
const orderEvents: OrderEvent[] = [
{
eventId: 'evt-001',
aggregateId: 'order-123',
eventType: 'OrderCreated',
version: 1,
timestamp: new Date('2026-04-07T09:00:00Z'),
data: {
customerId: 'cust-456',
items: [{ productId: 'prod-789', quantity: 2, price: 29.99 }],
},
},
{
eventId: 'evt-002',
aggregateId: 'order-123',
eventType: 'PaymentReceived',
version: 2,
timestamp: new Date('2026-04-07T09:01:00Z'),
data: { amount: 59.98, paymentMethod: 'credit_card' },
},
{
eventId: 'evt-003',
aggregateId: 'order-123',
eventType: 'OrderShipped',
version: 3,
timestamp: new Date('2026-04-07T14:30:00Z'),
data: { carrier: 'FedEx', trackingNumber: 'FX123456' },
},
]; Rebuilding State from Events
// The aggregate rebuilds its state by replaying events
class Order {
id: string = '';
customerId: string = '';
items: OrderItem[] = [];
status: string = 'unknown';
total: number = 0;
trackingNumber: string | null = null;
static fromEvents(events: OrderEvent[]): Order {
const order = new Order();
for (const event of events) {
order.apply(event);
}
return order;
}
private apply(event: OrderEvent): void {
switch (event.eventType) {
case 'OrderCreated':
this.id = event.aggregateId;
this.customerId = event.data.customerId as string;
this.items = event.data.items as OrderItem[];
this.total = this.items.reduce((sum, i) => sum + i.price * i.quantity, 0);
this.status = 'pending';
break;
case 'PaymentReceived':
this.status = 'paid';
break;
case 'OrderShipped':
this.status = 'shipped';
this.trackingNumber = event.data.trackingNumber as string;
break;
case 'OrderCancelled':
this.status = 'cancelled';
break;
}
}
}Projections: Building Read Models from Events
Event Sourcing stores events, not queryable state. Projections consume events and build read-optimized views. Think of them as materialized views over an event stream.
// Projection: build a read-optimized order summary table
class OrderSummaryProjection {
async handle(event: OrderEvent): Promise {
switch (event.eventType) {
case 'OrderCreated':
await this.db.query(`
INSERT INTO order_summaries (id, customer_id, status, total, created_at)
VALUES ($1, $2, 'pending', $3, $4)
`, [event.aggregateId, event.data.customerId, event.data.total, event.timestamp]);
break;
case 'OrderShipped':
await this.db.query(`
UPDATE order_summaries
SET status = 'shipped', tracking_number = $2, updated_at = $3
WHERE id = $1
`, [event.aggregateId, event.data.trackingNumber, event.timestamp]);
break;
case 'OrderCancelled':
await this.db.query(`
UPDATE order_summaries SET status = 'cancelled', updated_at = $2
WHERE id = $1
`, [event.aggregateId, event.timestamp]);
break;
}
}
} The power of projections: you can create multiple read models from the same events. One projection builds an order dashboard. Another feeds a search index. A third generates analytics. If you need a new read model, replay all historical events through a new projection -- no data migration needed.
When CQRS and Event Sourcing Make Sense
- Audit and compliance -- financial services, healthcare, and regulated industries that need a complete, tamper-proof record of every state change.
- Complex domains with business rules -- domains where the write model is fundamentally different from the read model (e.g., insurance policy underwriting vs. policy display).
- Read/write asymmetry -- systems with 100x more reads than writes, where the read path needs to be independently optimized and scaled.
- Temporal queries -- "What was the portfolio value on March 15?" or "Show me the order state before the last modification."
- Event replay for debugging -- reproduce production bugs by replaying the exact sequence of events that caused the issue.
When They Don't Make Sense
- Simple CRUD applications -- if your app is mostly forms that save to a database, CQRS adds layers of indirection with no benefit.
- Small teams -- the operational overhead of event stores, projections, and eventual consistency requires significant investment.
- Strong consistency requirements everywhere -- CQRS with separate read/write stores introduces eventual consistency. If your users can't tolerate stale reads, you'll fight the pattern constantly.
- Early-stage products -- you don't know your domain well enough yet. Event schemas are hard to change retroactively.
Watch out: Event schema evolution is the hardest problem in Event Sourcing. Once events are stored, they're immutable. If you change the structure of an
OrderCreatedevent, old events still have the old structure. You need upcasting (transforming old events to the new schema at read time) or versioned event handlers. Get this wrong and your projections break.
Event Store Options and Pricing
| Event Store | Type | Estimated Monthly Cost | Best For |
|---|---|---|---|
| EventStoreDB | Purpose-built event store | $0 (OSS) / $300+ (Cloud) | Dedicated event sourcing, built-in projections |
| PostgreSQL (append-only table) | Relational DB as event store | $50 - $500 (managed) | Teams already using PostgreSQL, simpler ops |
| Amazon DynamoDB | NoSQL event store | $100 - $600 | AWS-native, scales automatically |
| Apache Kafka | Event log + streaming | $400 - $1,200 (MSK) | High-throughput, stream processing integration |
| Azure Cosmos DB | Multi-model event store | $200 - $1,000 | Azure-native, change feed for projections |
| Marten (PostgreSQL) | .NET library over PostgreSQL | PostgreSQL cost only | .NET teams, document + event store in one |
Snapshots: Avoiding Replay Overhead
Replaying thousands of events to rebuild an aggregate gets slow. Snapshots solve this by periodically saving the current state alongside the event stream.
- Define a snapshot interval -- for example, every 100 events.
- Save the aggregate state as a snapshot with the version number of the last event.
- When loading an aggregate, load the most recent snapshot first, then replay only events after the snapshot version.
- The snapshot is a performance optimization -- the event stream is still the source of truth. You can delete and rebuild snapshots at any time.
// Loading an aggregate with snapshot support
async function loadOrder(orderId: string): Promise {
// Try to load latest snapshot
const snapshot = await snapshotStore.getLatest(orderId);
let order: Order;
let fromVersion: number;
if (snapshot) {
order = Order.fromSnapshot(snapshot.state);
fromVersion = snapshot.version + 1;
} else {
order = new Order();
fromVersion = 1;
}
// Replay events after snapshot
const events = await eventStore.getEvents(orderId, fromVersion);
for (const event of events) {
order.apply(event);
}
// Save new snapshot if needed
if (events.length > 100) {
await snapshotStore.save(orderId, order.toSnapshot(), order.version);
}
return order;
} Eventual Consistency: The Trade-Off You Must Accept
When your read model is built asynchronously from events, there's a delay between a write and when it appears in the read model. This is typically milliseconds, but it's not zero.
Practical strategies for handling it:
- Read-your-own-writes -- after a command succeeds, return the expected state to the client directly instead of querying the read model.
- Optimistic UI -- the frontend updates immediately and reconciles when the read model catches up.
- Polling or subscriptions -- the client subscribes to the event stream and updates when the relevant event arrives.
- Synchronous projections -- for critical read models, update them in the same transaction as the event write. This trades performance for consistency.
Optimistic Concurrency: The Part Every Tutorial Skips
Tutorials show the happy path where one actor writes to one aggregate at a time. Production is concurrent. Two API calls modify the same order simultaneously. Both read the current state (version=7), both produce an event, both try to append. One must lose.
// Append with optimistic concurrency -- this is the only safe way
async function appendEvents(
aggregateId: string,
expectedVersion: number,
newEvents: OrderEvent[],
): Promise<void> {
await db.tx(async (t) => {
// Conditional write: the row for this aggregate must still be at expectedVersion.
const result = await t.query(
`UPDATE aggregate_versions
SET version = $1
WHERE aggregate_id = $2 AND version = $3`,
[expectedVersion + newEvents.length, aggregateId, expectedVersion],
);
if (result.rowCount === 0) {
throw new ConcurrencyError(
`Aggregate ${aggregateId} was modified concurrently. Expected v${expectedVersion}.`,
);
}
// Now append the events. Atomic because we are in the same transaction.
for (const evt of newEvents) {
await t.query(
`INSERT INTO events (aggregate_id, version, event_type, data, ts)
VALUES ($1, $2, $3, $4, $5)`,
[aggregateId, evt.version, evt.eventType, evt.data, evt.timestamp],
);
}
});
}The losing write throws ConcurrencyError, the calling code catches it, re-reads the aggregate, replays the command against fresh state, and retries. This is standard optimistic concurrency, and it is non-negotiable for any event-sourced system. Skip it and you will get orders in impossible states within a week of production traffic.
Failure Modes: The Pitfalls That Derail First Attempts
Projection replay takes forever. You decide to add a new read model. To build it, you must replay every event from the beginning of time. On a 3-year-old system with 400M events, a single-threaded projector takes 11 hours. Build partitioning and parallel replay into your projector framework on day one, not the day you need a new view.
Schema evolution breaks old projections. You add a shippingAddress field to OrderCreated. Every event written before this week has no shippingAddress. Your projector crashes on replay. Fix: version your events (OrderCreatedV2), upcast old versions at read time, and never modify a stored event in place.
Eventual consistency surfaces in the UI. User clicks "Create Order," is redirected to the order list page, does not see their new order for 400ms. They think it failed and click "Create" again. You now have two orders. Fix: either return the command result directly to the client for immediate display, or use an optimistic UI that renders the expected state before the read model catches up.
The event store becomes the tightly-coupled god object. Four services now consume directly from the same raw event stream. You want to rename PaymentReceived.amount to PaymentReceived.amountCents for a bug fix. You cannot -- four downstream services would break. Fix: publish a versioned, stable integration event schema to other services, separate from your internal domain events.
Scaling reality: A well-tuned single PostgreSQL instance handles 10-30K events/second as an event store, which covers the vast majority of systems. You do not need Kafka or EventStoreDB for a Series-A SaaS. Reach for dedicated event stores when you need cross-datacenter replication, projection subscriptions built in, or sustained throughput above 50K/sec.
A Minimal Decision Framework
Boil everything above down to a table you can screenshot:
| If your system has... | Pattern to start with | Storage |
|---|---|---|
| CRUD shapes, no audit requirement | Plain 3-tier architecture | PostgreSQL |
| Read/write shape mismatch, no audit | CQRS, no Event Sourcing | Postgres + materialized views or a read replica |
| Read/write mismatch + 100x more reads | CQRS with denormalized read store | Postgres + Elasticsearch/Redis, synced via CDC |
| Audit/compliance requirement | Event Sourcing (CQRS usually falls out of it) | Postgres append-only table or EventStoreDB |
| Full historical replay + temporal queries | Event Sourcing + snapshots + projections | EventStoreDB, Marten, or Kafka + projector |
| 10K+ events/sec sustained | Event Sourcing with purpose-built store | Kafka/EventStoreDB, Cassandra for projections |
Frequently Asked Questions
Do I need Event Sourcing to use CQRS?
No. CQRS simply means separating your read and write models. You can implement CQRS with a traditional database for writes and a read replica, materialized view, or cache for reads. Event Sourcing is an orthogonal pattern that complements CQRS but is not required. Most teams should start with CQRS alone.
What is an event store?
An event store is an append-only database that persists events as the primary source of truth. Events are immutable and ordered by sequence number per aggregate. Purpose-built event stores like EventStoreDB offer built-in projections and subscriptions. PostgreSQL with an append-only table works well for simpler implementations.
How do I handle event schema changes?
Use upcasting to transform old events to the current schema at read time. Version your events with a schema version field. Never modify stored events -- they're immutable facts. Build your event handlers to tolerate missing optional fields and use default values for new fields.
What is the difference between CQRS and traditional CRUD?
In CRUD, the same model handles reads and writes. In CQRS, the write model enforces business rules and the read model is optimized for queries. This separation lets you scale reads and writes independently, use different storage technologies for each, and optimize each model for its specific purpose.
How do projections work in Event Sourcing?
Projections are event handlers that consume events and build read-optimized views. Each projection subscribes to relevant event types and updates a denormalized data store. You can create multiple projections from the same events for different query patterns. If a projection is corrupted, rebuild it by replaying all events.
What are snapshots in Event Sourcing?
Snapshots are periodic saves of an aggregate's current state. Instead of replaying all events from the beginning, you load the latest snapshot and replay only events after it. Snapshots are a performance optimization -- the event stream remains the source of truth and snapshots can be rebuilt at any time.
Is CQRS overkill for my application?
If your application is primarily CRUD with similar read and write patterns, yes. CQRS adds value when reads and writes have fundamentally different shapes, when you need independent scaling, or when your read patterns are complex enough to benefit from denormalized views. A good test: if your queries require multiple joins across many tables, a read-optimized model would help.
Start With the Problem, Not the Pattern
CQRS and Event Sourcing are solutions to specific problems. If you don't have read/write asymmetry, you don't need CQRS. If you don't need audit trails or temporal queries, you don't need Event Sourcing. Start with a well-structured application using a traditional database. When you hit a wall -- queries are slow because the write schema doesn't match the read patterns, or you need to reconstruct past state -- that's when these patterns earn their complexity. Apply them surgically to the bounded contexts that need them, not across your entire system.
Written by
Abhishek Patel
Infrastructure engineer with 10+ years building production systems on AWS, GCP, and bare metal. Writes practical guides on cloud architecture, containers, networking, and Linux for developers who want to understand how things actually work under the hood.
Related Articles
SQLite at the Edge: When libSQL Beats Postgres
SQLite at the edge via libSQL embedded replicas and Cloudflare D1 delivers 2-5ms reads worldwide versus 20-100ms for Postgres read replicas. Real benchmarks, pricing comparisons, production failure modes, and a decision framework for when edge SQLite wins and when Postgres-with-replicas is still the right call.
15 min read
DevOpsWebContainers and StackBlitz: Browser-Native Dev Environments in 2026
Real Node.js compiled to WebAssembly running inside the browser tab. What works (Next.js dev, npm install, SQLite via WASM), what doesn't (native modules, Postgres, Python), and the use cases that actually changed in 2026: docs, interviews, AI agent sandboxes, SDK onboarding.
12 min read
AI/ML EngineeringClaude Agent SDK: Build Custom AI Agents
Build production Claude agents in TypeScript or Python with the official Agent SDK. Tool-use loop, MCP integration, extended thinking, guardrails, and observability — end-to-end tutorial in under 45 minutes.
16 min read
Enjoyed this article?
Get more like this in your inbox. No spam, unsubscribe anytime.