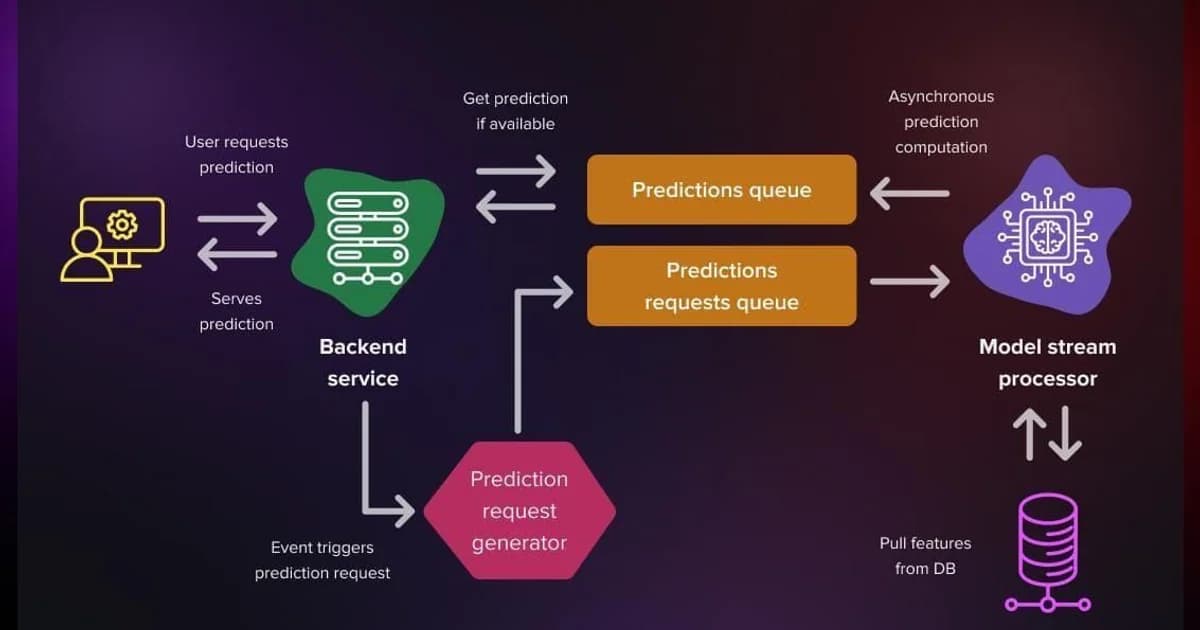
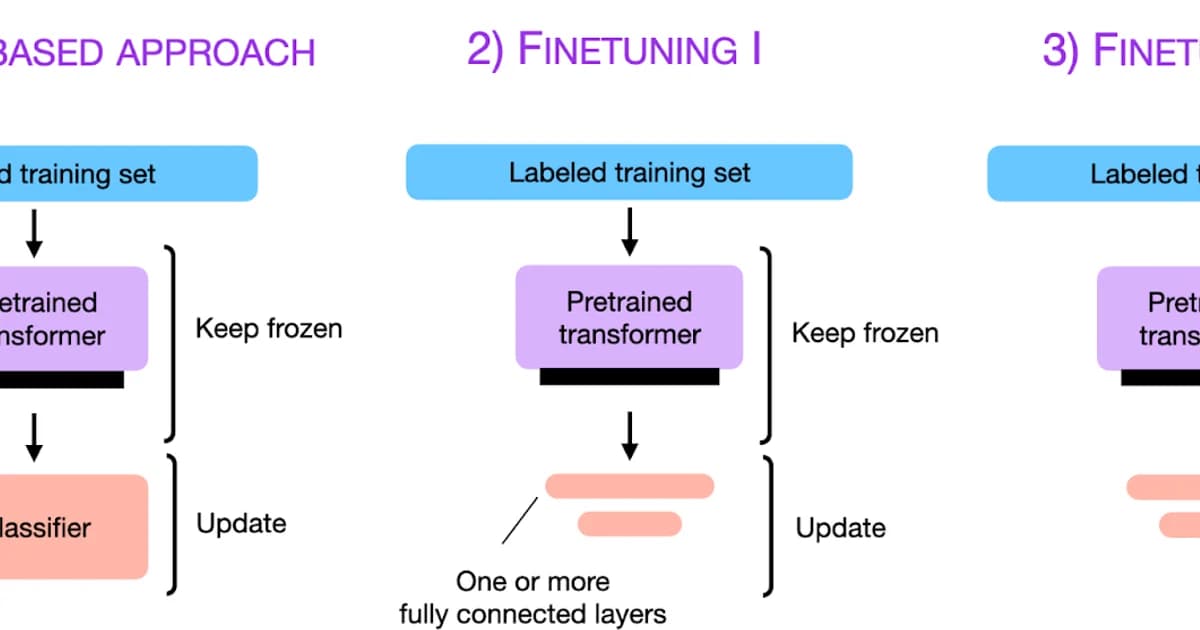
AI/ML Engineering
Ollama vs vLLM vs llama.cpp: LLM Inference Engines Compared
Benchmarks and architecture comparison of Ollama, vLLM, and llama.cpp. Tokens/sec at 7B through 70B, quantization trade-offs, concurrent throughput, VRAM requirements, and a clear decision framework for local dev, production, and edge.
13 min read·