Fine-Tuning vs Prompt Engineering: Choosing the Right Approach
A practical guide to choosing between prompt engineering and fine-tuning for LLMs -- techniques, costs, LoRA/QLoRA, and a decision framework for production systems.
Infrastructure engineer with 10+ years building production systems on AWS, GCP,…
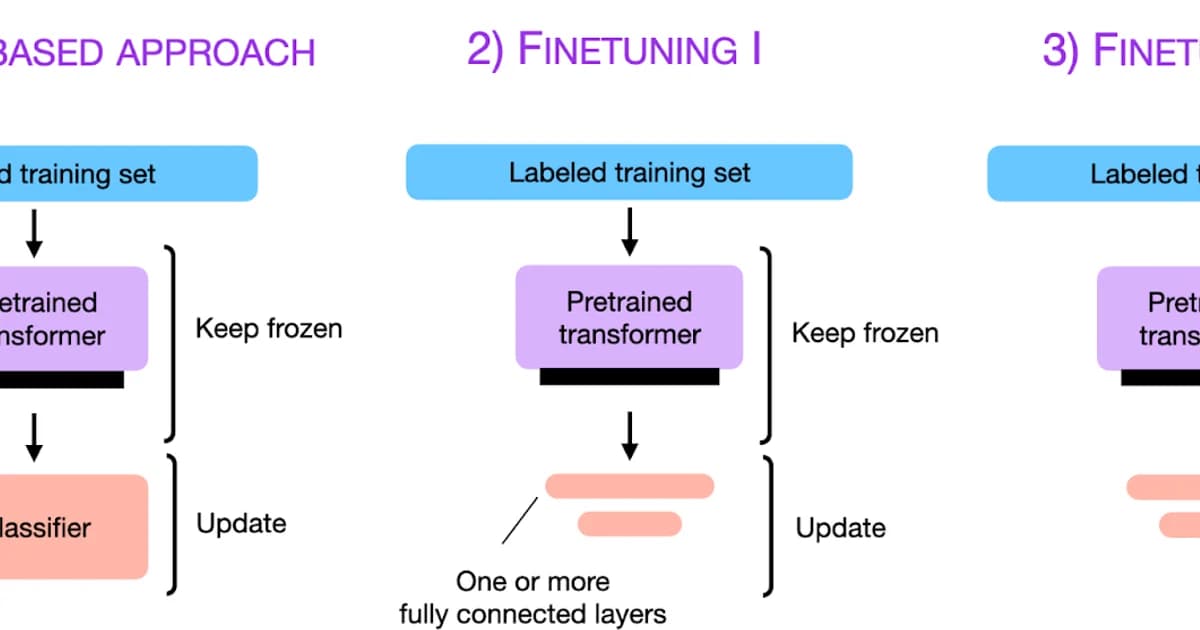
Prompt Engineering vs Fine-Tuning, Side by Side
Both techniques solve the same problem -- the base LLM is close to what you need but not quite right -- and they attack it from opposite ends. Prompt engineering changes what you send into the model on every request. Fine-tuning changes the model itself, so the new behavior is baked in and does not need to be re-specified per call. Here is every axis that matters, lined up:
| Axis | Prompt engineering | Fine-tuning (LoRA / QLoRA / full) |
|---|---|---|
| What changes | The input tokens, per request | The model weights, permanently |
| Setup time | Minutes -- write, test, iterate | Days to weeks -- curate data, train, evaluate |
| Upfront cost | $0 | $10-10,000+ (compute) + 40-80 hours of data prep |
| Per-request cost | Higher (long system prompt + few-shot ex on every call) | Lower (internalized behavior = shorter prompt) |
| Data needed | 0-20 examples (few-shot) | 100-10,000+ labeled examples |
| Iteration loop | Seconds -- change a string, re-run | Hours per training run |
| Consistency | Good with temperature=0 and JSON schema | Excellent -- behavior is intrinsic |
| Portability | Prompts run on any comparable model | Locked to the specific base model version |
| Decay when base model updates | Minimal -- often improves | Significant -- may need retraining |
| Who can do it | Any engineer with API access | Engineer + ML tooling + GPU access |
| Best for | Format, classification, extraction, reasoning scaffolds | Brand voice, domain vocabulary, complex output schemas |
That table is enough for 80 percent of decisions: if the row that matters most to you -- speed, cost, iteration velocity, or portability -- sits on the prompt-engineering side, start there and only move right when prompts demonstrably hit a ceiling on a real evaluation set. The remaining 20 percent of decisions depend on how you use each technique, so the next two sections cover the prompt patterns that actually matter in production (few-shot, chain-of-thought, structured output) and the fine-tuning methods that keep the GPU bill sane (LoRA and QLoRA rather than full fine-tuning).
Prompt Engineering in Practice: The Three Techniques That Actually Ship
Few-Shot Prompting
Provide 2-5 examples of input-output pairs before your actual request. The model pattern-matches against your examples. This is surprisingly effective for formatting, classification, and extraction tasks.
Classify the following support tickets by priority.
Ticket: "Site is completely down, no pages loading"
Priority: P0 - Critical
Ticket: "Logo appears slightly blurry on retina displays"
Priority: P3 - Low
Ticket: "Payment processing failing for all credit cards"
Priority: P0 - Critical
Ticket: "User reports slow dashboard load times during peak hours"
Priority:
Chain-of-Thought (CoT)
Ask the model to reason step by step before giving its final answer. This dramatically improves accuracy on math, logic, and multi-step reasoning tasks. The reasoning doesn't need to be shown to users -- you can extract just the final answer.
Determine if this insurance claim should be approved or denied.
Think through each policy criterion step by step before giving your decision.
Policy criteria:
1. Claim must be filed within 30 days of incident
2. Deductible of $500 applies
3. Maximum coverage is $50,000
4. Pre-existing conditions are excluded
Claim details:
- Filed: 15 days after incident
- Amount: $12,000
- Type: Water damage from burst pipe
- Note: Previous claim for water damage 2 years ago (different cause)
Step-by-step analysis:
Structured Output
Constrain the model to output valid JSON, XML, or other structured formats by specifying the exact schema in your prompt. Most modern APIs (OpenAI, Anthropic, Google) support structured output natively with JSON schema enforcement.
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-4o",
response_format={
"type": "json_schema",
"json_schema": {
"name": "ticket_classification",
"schema": {
"type": "object",
"properties": {
"priority": {"type": "string", "enum": ["P0", "P1", "P2", "P3"]},
"category": {"type": "string"},
"summary": {"type": "string"}
},
"required": ["priority", "category", "summary"]
}
}
},
messages=[{"role": "user", "content": "Classify: Payment API returning 500 errors"}]
)
Pro tip: Before you invest in fine-tuning, exhaust every prompt engineering technique. Write a detailed system prompt. Add few-shot examples. Use chain-of-thought. Enforce structured output. In my experience, 80% of "we need to fine-tune" conclusions are actually "we need a better prompt" conclusions.
What Is Fine-Tuning?
Definition: Fine-tuning is the process of further training a pre-trained language model on a specific dataset to modify its weights, teaching it new behaviors, styles, or domain knowledge that persist across all future inferences without needing prompt-level instructions.
Fine-tuning changes the model itself. After fine-tuning, the model behaves differently even with a basic prompt. This is powerful when you need consistent behavior that's too complex or verbose to encode in a prompt every time.
When Fine-Tuning Wins Over Prompt Engineering
- Consistent style or voice -- you need every response to match a specific brand tone, writing style, or vocabulary that few-shot examples can't reliably enforce
- Complex output formats -- the model needs to produce specialized formats (medical notes, legal documents, code in a proprietary DSL) that are hard to describe in a prompt
- Latency reduction -- fine-tuning can replace long system prompts and few-shot examples with internalized behavior, reducing input tokens and speeding up responses
- Cost reduction at scale -- if your prompt uses 2000 tokens of examples on every request, fine-tuning those patterns into the model saves those tokens on millions of requests
- Domain-specific reasoning -- the model needs to apply specialized knowledge (medical, legal, financial) more reliably than prompt-level instructions achieve
Fine-Tuning Methods: Full, LoRA, and QLoRA
| Method | What It Does | GPU Memory | Training Time | Quality |
|---|---|---|---|---|
| Full fine-tuning | Updates all model parameters | Very high (4x model size) | Hours to days | Best possible |
| LoRA | Trains small adapter matrices, freezes base weights | Moderate (1.1-1.5x model size) | Minutes to hours | Near full fine-tuning |
| QLoRA | LoRA on a 4-bit quantized base model | Low (0.3-0.5x model size) | Minutes to hours | Slightly lower than LoRA |
LoRA (Low-Rank Adaptation) is the practical default. Instead of updating all billions of parameters, it adds small trainable matrices to attention layers. The base model stays frozen, and you train only 0.1-1% of the total parameters. The resulting adapter is small (often under 100MB) and can be hot-swapped at inference time.
from peft import LoraConfig, get_peft_model
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-3-8B")
lora_config = LoraConfig(
r=16, # rank of the adapter
lora_alpha=32, # scaling factor
target_modules=["q_proj", "v_proj"], # which layers to adapt
lora_dropout=0.05,
task_type="CAUSAL_LM"
)
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
# Output: trainable params: 6,553,600 || all params: 8,030,261,248 || trainable%: 0.08%
QLoRA goes further by quantizing the base model to 4-bit precision before applying LoRA. This lets you fine-tune a 70B parameter model on a single 48GB GPU -- something that would otherwise require a multi-GPU cluster.
Head-to-Head Comparison
| Factor | Prompt Engineering | Fine-Tuning |
|---|---|---|
| Time to implement | Minutes to hours | Days to weeks |
| Cost to start | $0 | $10-10,000+ (compute + data prep) |
| Data required | 0-20 examples | 100-10,000+ examples |
| Iteration speed | Immediate | Hours per experiment |
| Consistency | Good with structured output | Excellent |
| Model lock-in | Low (prompts are portable) | High (training is model-specific) |
| Maintenance | Update prompts as needed | Retrain when base model updates |
| Latency impact | Longer prompts = slower | Can reduce prompt length |
When Neither Is Enough: RLHF and DPO
Sometimes you need the model to not just produce a specific format or style, but to align its behavior with human preferences -- be more helpful, less harmful, or make better judgment calls. This is where RLHF (Reinforcement Learning from Human Feedback) and DPO (Direct Preference Optimization) come in.
RLHF trains a separate reward model on human preference data, then uses reinforcement learning to optimize the LLM's outputs against that reward model. It's how ChatGPT was aligned. DPO simplifies this by skipping the reward model entirely -- it directly optimizes the LLM using pairs of preferred and rejected responses. DPO is significantly easier to implement and has become the practical choice for most teams.
Watch out: RLHF and DPO require substantial preference data -- thousands of "this response is better than that response" comparisons. If you don't have that data or can't generate it reliably, these techniques will produce inconsistent results. They're powerful but not a shortcut.
Cost Comparison: Fine-Tuning Services
| Service | Cost Model | Typical Cost (1000 examples, 3 epochs) | Notes |
|---|---|---|---|
| OpenAI Fine-tuning (GPT-4o-mini) | Per training token | $3-10 | Simplest setup, limited customization |
| OpenAI Fine-tuning (GPT-4o) | Per training token | $20-60 | Higher quality base, higher cost |
| Together AI | Per GPU-hour | $5-50 | Open-source models, more control |
| Self-hosted (A100 80GB) | GPU rental | $2-8/hour | Full control, most setup work |
| AWS SageMaker | Instance hours | $5-30/hour | Enterprise integrations |
Pro tip: The hidden cost of fine-tuning isn't compute -- it's data preparation. Curating, cleaning, and formatting 1000+ high-quality training examples typically takes 40-80 hours of human effort. Factor that into your cost-benefit analysis before committing to the fine-tuning path.
A Decision Framework
- Start with prompt engineering. Write a detailed system prompt with few-shot examples. Measure output quality on 50+ test cases.
- If quality is below target, analyze failures. Are they consistency issues (same input, different output quality)? Prompt engineering can fix this with structured output and temperature=0.
- If failures are systematic -- the model consistently gets a specific type of task wrong despite good prompts -- collect 100+ examples of correct behavior and fine-tune.
- If you need alignment -- the model's judgment or tone is off in ways that can't be described in a prompt -- collect preference data and apply DPO.
- Re-evaluate after each model generation. A new base model release (GPT-5, Claude 4, Llama 4) may make your fine-tuning unnecessary. The frontier moves fast.
Frequently Asked Questions
Can I fine-tune and use prompt engineering together?
Absolutely, and you should. Fine-tuning sets the baseline behavior and style. Prompt engineering handles per-request customization, context injection, and edge cases. Most production systems use a fine-tuned model with carefully engineered prompts. They're complementary, not competing approaches.
How much training data do I need for fine-tuning?
For style and format changes, 100-500 high-quality examples often suffice with LoRA. For domain-specific knowledge, you'll need 1000-5000+ examples. Quality matters far more than quantity -- 200 perfect examples outperform 2000 noisy ones. Always validate with a held-out test set.
Does fine-tuning make the model smarter?
Not exactly. Fine-tuning adjusts behavior within the model's existing capability envelope. It won't make a 7B model reason like a 70B model. It will make the model more consistent, better formatted, and more aligned with your specific use case. For genuinely harder tasks, use a larger base model.
What's the difference between LoRA and full fine-tuning?
Full fine-tuning updates every parameter in the model, requiring massive GPU memory and compute. LoRA freezes the base model and trains small adapter matrices (typically 0.1% of parameters). The quality difference is small for most tasks, but LoRA is 10-100x cheaper to train and lets you swap adapters without reloading the base model.
Should I fine-tune an open-source model or use OpenAI's fine-tuning API?
If you're already using OpenAI's models, their fine-tuning API is the fastest path -- no infrastructure to manage. If you need full control over the model, want to avoid per-token inference costs, or have data privacy requirements, fine-tune an open-source model like Llama 3 on your own infrastructure or via Together AI.
How do I know if my prompt engineering has maxed out?
Run a systematic evaluation. If you've tried multiple prompt variants, added few-shot examples, used chain-of-thought, and enforced structured output -- and your accuracy on a test set of 50+ examples is still below your target -- prompt engineering has likely hit its ceiling for your task. That's your signal to explore fine-tuning.
What is DPO and when should I use it instead of fine-tuning?
Direct Preference Optimization trains a model to prefer certain response styles over others using pairs of "better" and "worse" responses. Use it when standard fine-tuning produces technically correct but tonally wrong outputs -- when the model needs better judgment rather than better knowledge. DPO requires preference data but is simpler to implement than RLHF.
The Pragmatic Path Forward
I've seen teams burn months and tens of thousands of dollars on fine-tuning when a well-crafted prompt would have solved their problem in an afternoon. I've also seen teams contort themselves into increasingly complex prompt chains when a simple fine-tune on 200 examples would have given them the consistency they needed. The key is measuring before deciding. Build an evaluation set, measure your baseline, try prompt engineering first, and only fine-tune when you have evidence it's needed. That's not a cop-out -- it's engineering discipline applied to a space that desperately needs it.
Written by
Abhishek Patel
Infrastructure engineer with 10+ years building production systems on AWS, GCP, and bare metal. Writes practical guides on cloud architecture, containers, networking, and Linux for developers who want to understand how things actually work under the hood.
Related Articles
LLM Latency: TTFT, ITL, and Why End-User Latency Isn't What You Think
LLM latency decomposes into TTFT (time to first token, 300-1500ms), ITL (inter-token, 10-30ms), and total time. Each has different causes and fixes. Why streaming dominates UX, when Cerebras/Groq beat Claude on speed, and the optimization playbook.
11 min read
DevOpsPython uv vs pip vs Poetry vs PDM: Speed Benchmarks 2026
Real benchmarks: uv installs Django + ML stack in 8s vs pip's 90s, Poetry's 50s, PDM's 38s. Why uv is fast (Rust + parallelism + PubGrub), what pip still does that uv doesn't, migration paths, and where Poetry's ergonomics still win.
12 min read
AI/ML EngineeringSelf-Hosting LLMs from India: Providers, Latency & INR Pricing (2026)
A practical comparison of self-hosting LLMs on Indian GPU clouds including E2E Networks, Tata TIR, and Yotta Shakti Cloud, with INR pricing inclusive of 18% GST, latency tests from Mumbai, Bangalore, Chennai, and Delhi, and DPDP Act 2023 compliance notes.
15 min read
Enjoyed this article?
Get more like this in your inbox. No spam, unsubscribe anytime.