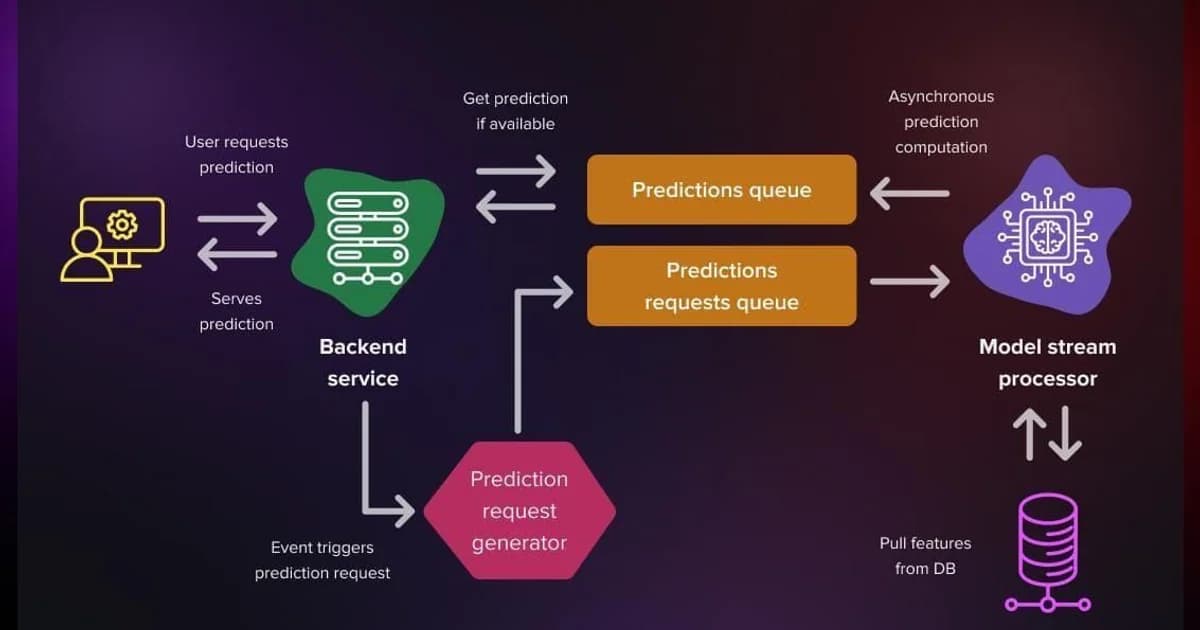
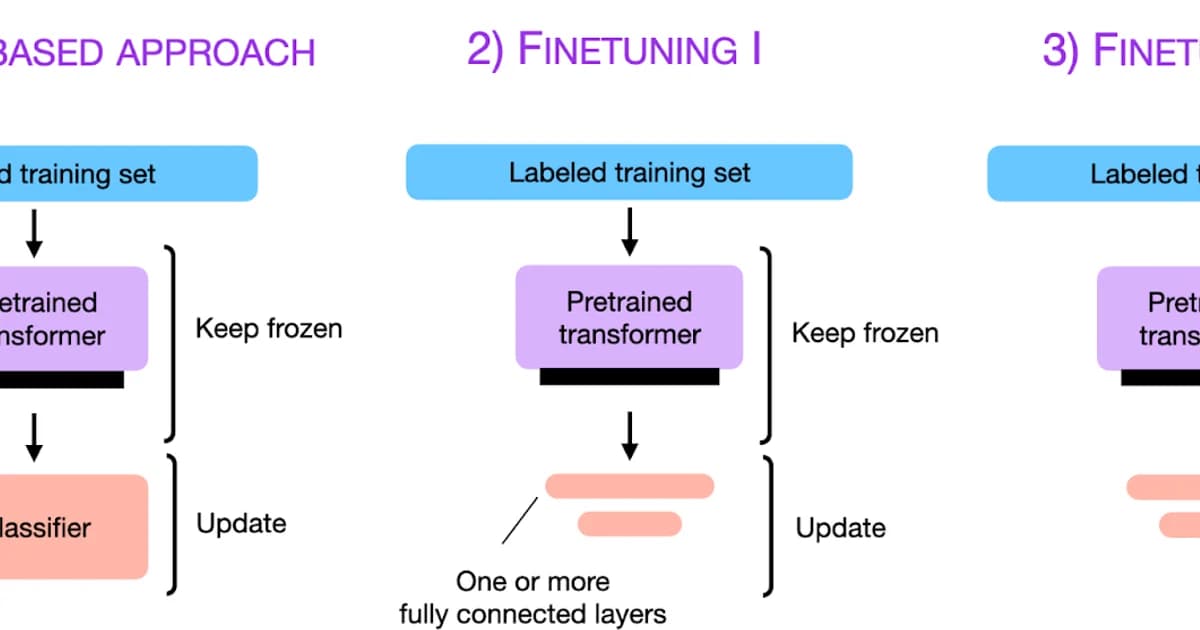
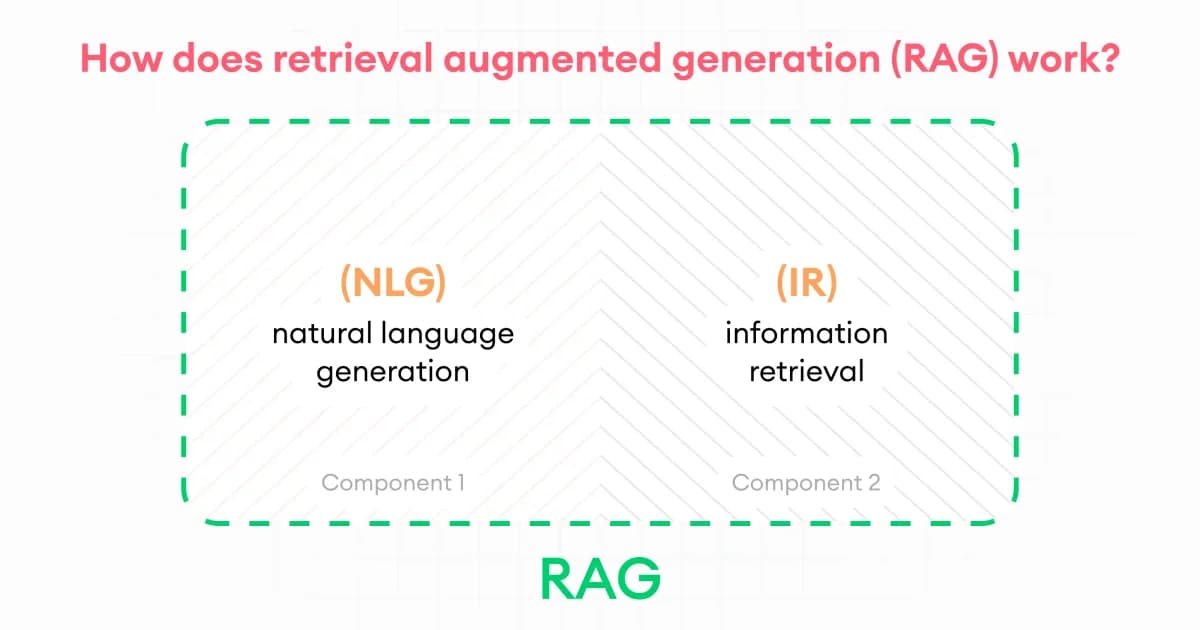
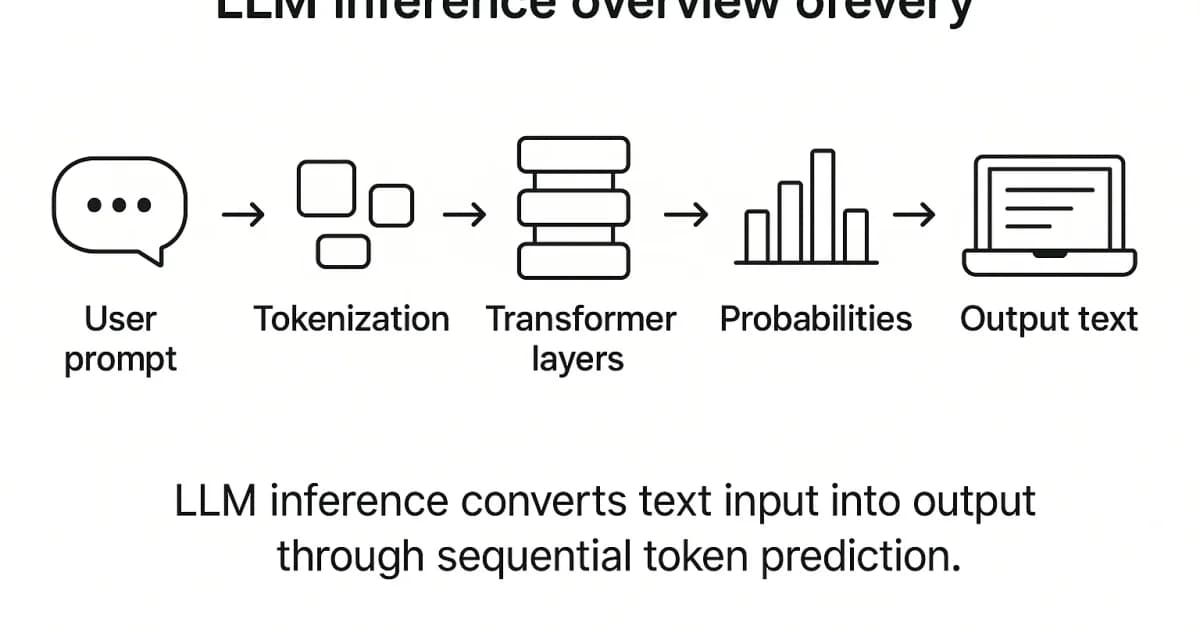
AI/ML Engineering
AI Observability: How to Monitor and Debug LLM Applications
A practical guide to monitoring LLM applications in production -- input/output logging, cost tracking, quality metrics, and a comparison of LangSmith, Langfuse, and Arize.
10 min read·