Event-Driven Architecture: When It Makes Sense and When It Doesn't
Event-driven architecture decouples services through message brokers like Kafka, RabbitMQ, and SNS/SQS. Learn when EDA is the right choice, how to implement it, and the patterns that make it work in production.
Infrastructure engineer with 10+ years building production systems on AWS, GCP,…
Event-Driven Architecture Is Forty Years Old -- The Managed-Broker Era Changed the Math
IBM's MQ Series shipped in 1993. TIBCO Rendezvous, the first widely-deployed publish-subscribe bus, landed in 1994 and spent the next decade running the trading floors of Goldman, Morgan Stanley, and most of Wall Street. Apache Kafka, which most engineers now treat as synonymous with event-driven architecture, was open-sourced by LinkedIn in January 2011 -- a full seventeen years after the pattern was already running global finance. The idea that services should communicate by emitting past-tense facts, not by calling each other directly, has been production-proven for longer than most of us have been writing code.
What changed wasn't the pattern; it was the operational cost. Running a highly-available message broker in 2005 meant three rack-mounted servers, a Solaris licence, and a storage engineer who knew TIBCO's backpressure quirks by heart. By 2015, Amazon SQS (launched 2006), Kafka on Confluent Cloud (2017), and Google Pub/Sub (2015) had turned the broker into a line item. You can now go from zero to a production event bus in an afternoon for $30 a month. That's the shift that makes EDA relevant to teams of five instead of teams of five hundred.
The accessibility is also where most teams now get it wrong. Event-driven architecture decouples producers from consumers through a broker -- Service A emits OrderPlaced and any interested consumer reacts independently, instead of Service A synchronously calling Services B, C, and D. That single design decision changes how you build, deploy, and debug distributed systems, and adopting it too early -- before you have more than two consumers of any event -- adds debugging complexity without buying you anything. The rest of this guide is the practical shape of EDA in 2026: the difference between events, commands, and messages (confusing them is the fastest path to a tangled system), which broker fits which workload, and the four production patterns -- order pipelines, saga orchestration, event sourcing, and CQRS -- that are worth the operational overhead, and the three that aren't.
Events vs Commands vs Messages
Before you start publishing events everywhere, you need to understand the three types of messages in a distributed system. Confusing them is the fastest way to build a tangled mess.
| Type | Intent | Coupling | Example |
|---|---|---|---|
| Event | Notification that something happened | Low — producer doesn't know consumers | OrderPlaced, UserRegistered |
| Command | Request for a specific action | High — sender expects a specific handler | SendEmail, ChargeCard |
| Message | Generic data transport | Varies | Any payload on a queue or topic |
Events are past-tense facts: "this happened." Commands are imperative requests: "do this." When you treat commands as events (or vice versa), you lose the benefits of decoupling. An OrderPlaced event is fine — any service can react to it. A SendConfirmationEmail command should go to a specific queue with a single consumer.
Pro tip: Name your events in past tense (
OrderPlaced,PaymentProcessed) and your commands in imperative form (ProcessPayment,SendNotification). This naming convention alone prevents half the confusion in event-driven systems.
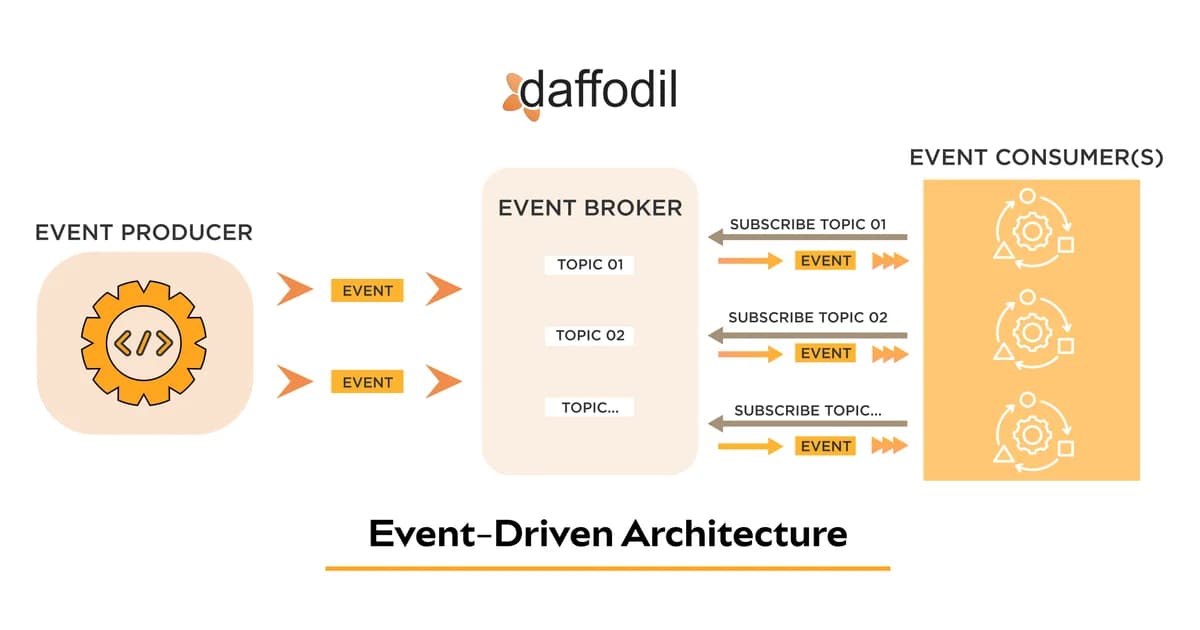
Core Components of an Event-Driven System
Every EDA implementation has three moving parts. Here's how they fit together:
1. Event Producers
Any service that emits events when state changes. Your order service publishes OrderPlaced when a customer checks out. Your payment service publishes PaymentCompleted after a charge succeeds. Producers should publish events as close to the state change as possible — ideally in the same transaction.
2. Message Broker
The infrastructure that receives, stores, and routes events. This is your Kafka cluster, your RabbitMQ instance, or your SNS/SQS setup. The broker decouples producers from consumers in time (async processing) and space (different services, different machines).
3. Event Consumers
Services that subscribe to events and react. The email service listens for OrderPlaced and sends a confirmation. The inventory service listens for the same event and decrements stock. Each consumer processes events independently, at its own pace.
Message Broker Comparison
Choosing the right broker is the most consequential infrastructure decision in an event-driven system. Here's how the major options compare:
| Broker | Model | Ordering | Replay | Best For |
|---|---|---|---|---|
| Apache Kafka | Log-based (pull) | Per-partition | Yes — configurable retention | High-throughput streaming, event sourcing |
| RabbitMQ | Queue-based (push) | Per-queue (single consumer) | No — consumed messages are deleted | Task queues, RPC, routing |
| Amazon SQS | Queue-based (pull) | FIFO queues only | No | Simple async processing, AWS-native |
| Amazon SNS + SQS | Pub/sub + queue | FIFO topics only | No | Fan-out to multiple consumers |
| Google Pub/Sub | Pub/sub (pull/push) | Per-key ordering | Seek to timestamp | GCP-native event streaming |
| Azure Service Bus | Queue + topic | Sessions | No | Enterprise messaging, Azure-native |
Warning: Don't pick Kafka just because it's popular. If you're processing fewer than 10,000 events per second and don't need replay, SQS or RabbitMQ is simpler to operate and cheaper to run. Kafka's operational overhead is real — even with managed services.
Synchronous vs Asynchronous Communication
Understanding when to use each pattern is critical. Not every interaction should be event-driven.
| Aspect | Synchronous (REST/gRPC) | Asynchronous (Events) |
|---|---|---|
| Latency | Immediate response | Eventual processing |
| Coupling | Tight — caller waits for response | Loose — fire and forget |
| Failure handling | Caller must handle errors | Broker retries; dead-letter queues |
| Scalability | Limited by slowest service | Consumers scale independently |
| Debugging | Stack traces, request IDs | Distributed tracing, correlation IDs |
| Use when | You need a response to continue | Downstream work can happen later |
The rule of thumb: if the user is waiting for the result, keep it synchronous. If the work can happen after you've responded to the user, make it asynchronous. Order placement? Synchronous for the payment, async for the confirmation email.
Real-World EDA Patterns
Order Processing Pipeline
This is the textbook use case. An e-commerce checkout triggers a cascade of downstream work:
OrderPlaced --> [Email Service] --> Send confirmation
--> [Inventory Service] --> Decrement stock
--> [Warehouse Service] --> Create pick list
--> [Analytics Service] --> Track conversion
--> [Fraud Service] --> Run fraud checkEach consumer processes the event independently. If the analytics service goes down, orders still process. If the email service is slow, checkout latency is unaffected. That's the power of decoupling.
Audit Logging and Change Data Capture
Every state change in your system emits an event. A dedicated audit consumer writes these events to an append-only store. You get a complete history of every change without polluting your business services with logging logic. Change data capture (CDC) takes this further — tools like Debezium read your database's transaction log and publish events for every row change.
Fan-Out Notifications
A single event triggers multiple notification channels: push notification, email, SMS, in-app message. SNS + SQS is built for exactly this pattern — publish once to an SNS topic, fan out to multiple SQS queues, each with its own consumer.
Implementation: SNS + SQS in AWS
Here's a practical example using AWS CDK to set up a fan-out pattern:
import * as cdk from 'aws-cdk-lib';
import * as sns from 'aws-cdk-lib/aws-sns';
import * as sqs from 'aws-cdk-lib/aws-sqs';
import * as subscriptions from 'aws-cdk-lib/aws-sns-subscriptions';
const orderTopic = new sns.Topic(this, 'OrderEventsTopic', {
topicName: 'order-events',
});
// Each consumer gets its own queue
const emailQueue = new sqs.Queue(this, 'EmailQueue', {
queueName: 'order-email-notifications',
visibilityTimeout: cdk.Duration.seconds(30),
deadLetterQueue: {
queue: new sqs.Queue(this, 'EmailDLQ', {
queueName: 'order-email-dlq',
retentionPeriod: cdk.Duration.days(14),
}),
maxReceiveCount: 3,
},
});
const inventoryQueue = new sqs.Queue(this, 'InventoryQueue', {
queueName: 'order-inventory-updates',
visibilityTimeout: cdk.Duration.seconds(60),
});
// Subscribe queues to the topic
orderTopic.addSubscription(
new subscriptions.SqsSubscription(emailQueue)
);
orderTopic.addSubscription(
new subscriptions.SqsSubscription(inventoryQueue)
);Publishing an Event
import { SNSClient, PublishCommand } from '@aws-sdk/client-sns';
const sns = new SNSClient({ region: 'us-east-1' });
async function publishOrderPlaced(order: Order) {
await sns.send(new PublishCommand({
TopicArn: process.env.ORDER_TOPIC_ARN,
Message: JSON.stringify({
eventType: 'OrderPlaced',
timestamp: new Date().toISOString(),
correlationId: order.id,
data: {
orderId: order.id,
customerId: order.customerId,
totalAmount: order.total,
items: order.items,
},
}),
MessageAttributes: {
eventType: {
DataType: 'String',
StringValue: 'OrderPlaced',
},
},
}));
}Consuming Events with Idempotency
import { SQSEvent } from 'aws-lambda';
export async function handler(event: SQSEvent) {
for (const record of event.Records) {
const message = JSON.parse(record.body);
const snsMessage = JSON.parse(message.Message);
// Idempotency check — skip if already processed
const processed = await db.processedEvents.findUnique({
where: { eventId: snsMessage.correlationId },
});
if (processed) continue;
// Process the event
await sendOrderConfirmation(snsMessage.data);
// Mark as processed
await db.processedEvents.create({
data: {
eventId: snsMessage.correlationId,
processedAt: new Date(),
},
});
}
}Pro tip: Always include a
correlationIdin your event payload. It lets you trace a single business action across every service that touches it. Without it, debugging distributed failures becomes a nightmare of timestamp correlation and guesswork.
Making EDA Manageable: Essential Patterns
Idempotent Consumers
Messages can be delivered more than once. Your SQS consumer might process the same event twice if a Lambda times out after processing but before deleting the message. Every consumer must handle duplicate delivery gracefully. Store processed event IDs and check before processing — or design your operations to be naturally idempotent (upserts instead of inserts).
Dead-Letter Queues
When a consumer fails to process a message after several retries, it goes to a dead-letter queue (DLQ). DLQs prevent poison messages from blocking your entire pipeline. Monitor your DLQs — a growing DLQ means something is wrong. Set up alerts and build tooling to replay DLQ messages after you've fixed the bug.
Event Schema Evolution
Your event schemas will change. New fields get added, old fields become irrelevant. You need a strategy:
- Always add, never remove — new fields are optional, old consumers ignore them
- Use a schema registry — Confluent Schema Registry or AWS Glue Schema Registry validates events at publish time
- Version your events — include a
schemaVersionfield so consumers can handle different versions - Test backward compatibility — before deploying a schema change, verify that existing consumers won't break
Correlation IDs and Distributed Tracing
In a synchronous system, you get a stack trace. In an event-driven system, a request might touch five services over ten minutes. Assign a correlation ID at the entry point and propagate it through every event. Use OpenTelemetry to connect the dots. Without this, debugging production issues is like solving a jigsaw puzzle with missing pieces.
Managed Message Broker Pricing
Cost is a real factor when choosing a broker. Here's what you're looking at for a mid-scale workload (roughly 100 million messages per month):
| Service | Pricing Model | Estimated Monthly Cost | Notes |
|---|---|---|---|
| Amazon SQS | $0.40 per million requests | $40 - $80 | Cheapest option; FIFO queues cost 2x |
| Amazon SNS | $0.50 per million publishes | $50 (publish only) | Add SQS cost for each subscriber queue |
| Amazon MSK (Kafka) | Instance-based + storage | $400 - $1,200 | Minimum 2 brokers; Serverless from $0.10/hr per partition |
| Confluent Cloud | CKU-based + storage + network | $500 - $2,000 | Fully managed; includes Schema Registry |
| CloudAMQP (RabbitMQ) | Plan-based | $99 - $499 | Tiger plan for production; includes monitoring |
| Google Pub/Sub | $40 per TiB ingested | $50 - $150 | Competitive pricing; good GCP integration |
Note: These are estimates for moderate workloads. At high volume (billions of messages), SQS and SNS remain the most cost-effective. Kafka-based solutions make financial sense when you need replay, stream processing, or event sourcing — features that justify the premium.
When Event-Driven Architecture Makes Sense
EDA isn't universally better than synchronous communication. It's a tool, and like all tools, it has specific use cases where it shines:
- Fan-out processing — one event triggers multiple independent reactions
- Workload decoupling — a slow consumer shouldn't block the producer
- Audit and compliance — you need a complete record of every state change
- Cross-team boundaries — teams can consume events without coordinating deployments
- Spike absorption — queues buffer traffic spikes so consumers process at a steady rate
When Event-Driven Architecture Doesn't Make Sense
I've seen teams adopt EDA when they shouldn't. Here's when to stay synchronous:
- Simple CRUD applications — if your app has five endpoints and two services, you don't need a message broker
- Strong consistency requirements — if you need an immediate, consistent response, events add complexity without benefit
- Small teams — the operational overhead of running and monitoring brokers, DLQs, and schema registries requires investment
- Request-response patterns — if the caller needs a response to continue, async adds latency and complexity
Organizational Maturity for EDA
Technical architecture is only half the story. Event-driven systems require organizational maturity:
- Event ownership — every event needs a clear owner. Who defines the schema? Who handles breaking changes?
- Monitoring and alerting — you need dashboards for queue depth, consumer lag, DLQ size, and processing latency
- Runbooks — when a DLQ fills up at 2 AM, on-call engineers need clear steps to diagnose and replay
- Schema governance — a schema registry and review process prevents breaking changes from reaching production
- Testing strategy — integration tests must cover async flows, including failure scenarios and retry behavior
If your team doesn't have the capacity for this operational investment, start with a simpler architecture. You can always introduce events later when the pain of synchronous coupling becomes real.
Frequently Asked Questions
What is the difference between event-driven and message-driven architecture?
Event-driven architecture focuses on broadcasting state changes (events) to any interested consumer. Message-driven architecture is broader and includes point-to-point commands and request-reply patterns. EDA is a subset of message-driven design. In practice, most systems use both: events for notifications and commands for directed work.
Can I use event-driven architecture with a monolith?
Yes, and it's actually a great starting point. A monolith can publish events to a broker for async processing — background jobs, notifications, analytics — without a full microservices migration. This gives you the decoupling benefits of events without the operational overhead of distributed services.
How do I handle event ordering in distributed systems?
Most brokers offer ordering guarantees per partition or per queue. Kafka guarantees order within a partition — use the entity ID as the partition key. SQS FIFO queues guarantee order per message group ID. Design your system so that events that must be ordered share a partition key.
What happens when a consumer is down?
The broker retains unprocessed messages until the consumer recovers. SQS retains messages for up to 14 days. Kafka retains them based on your retention policy (often 7 days or more). This durability is one of EDA's biggest advantages over synchronous calls — temporary outages don't cause data loss.
How do I debug issues in an event-driven system?
Use correlation IDs in every event, implement distributed tracing with OpenTelemetry, and centralize your logs. Tools like Jaeger or AWS X-Ray visualize the path of a request across services. Monitor consumer lag and DLQ depth to catch problems early. It's harder than debugging synchronous systems, but manageable with the right tooling.
Should I use Kafka or SQS for my event-driven system?
If you need event replay, stream processing, or handle over 100,000 events per second, Kafka is the better choice. If you need simple async processing with minimal operational overhead and you're on AWS, SQS is cheaper and easier. Most applications start fine with SQS and graduate to Kafka when specific requirements demand it.
What is eventual consistency and how does it affect EDA?
Eventual consistency means that after an event is published, different parts of the system may show different states until all consumers have processed the event. A user might place an order and see it confirmed, but the inventory count takes a few seconds to update. Design your UI to accommodate this delay and communicate processing status clearly.
Written by
Abhishek Patel
Infrastructure engineer with 10+ years building production systems on AWS, GCP, and bare metal. Writes practical guides on cloud architecture, containers, networking, and Linux for developers who want to understand how things actually work under the hood.
Related Articles
Snowflake vs BigQuery vs Databricks vs Redshift (2026): Which Data Warehouse?
Snowflake wins on concurrency, BigQuery on serverless simplicity, Databricks on ML, Redshift on AWS depth. Real 2026 pricing, TPC-DS benchmarks, and a clear decision matrix.
16 min read
AI/ML EngineeringRunPod vs Vast.ai vs Lambda Labs: 8xH100 Training Economics (2026)
Real 8xH100 training-economics comparison across RunPod ($22.32/hr Secure Cloud), Vast.ai (spot $12.16/hr floor), and Lambda Labs (reserved $14.80/hr). MFU benchmarks, break-even math for spot vs reserved, interruption rates, and which provider wins per job shape.
16 min read
AI/ML EngineeringBest Cloud GPU Providers for AI Training (2026): RunPod vs Lambda Labs vs Paperspace vs Vast.ai vs Together AI
Benchmarked comparison of RunPod, Lambda Labs, Paperspace, Vast.ai, and Together AI for AI training in 2026. Real H100 hourly rates, multi-node reliability, spin-up times, and a decision matrix for picking the right cloud GPU provider.
17 min read
Enjoyed this article?
Get more like this in your inbox. No spam, unsubscribe anytime.